[Learning Deep Features for Discriminative Localization]
1. Introduction
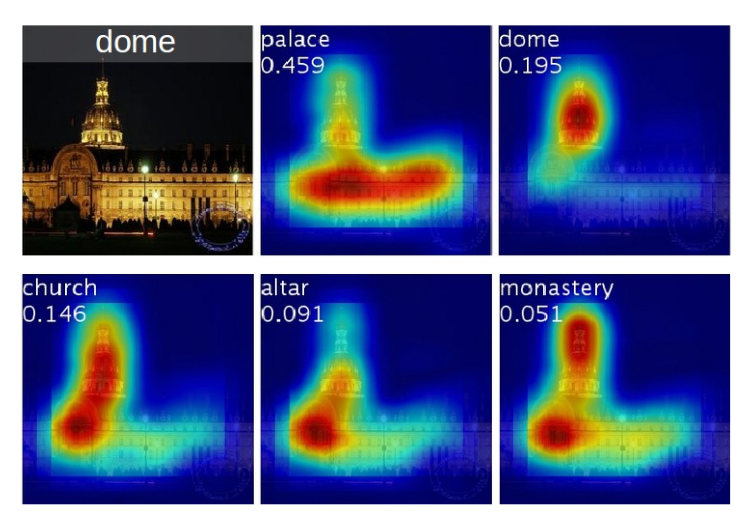
보통 CNN의 구조를 생각해보면, Input - Conv Layers - FC Layers 으로 이루어졌다. 즉, CNN은 마지막 컨벌루션 레이어를 FC-Layer 들로 바꾸고, Softmax 함수를 통해 특정 이미지를 특정 클라스로 분류하는 데 매우 뛰어난 성능을 보여준다. 하지만 이렇게 CNN 의 마지막 레이어를 FC-Layer 로 Flatten 시킬때 우리는 그 Convolution 이 가지고 있던 각 픽셀들의 위치 정보를 잃게 된다. 따라서 Classifying 정확도가 아무리 뛰어날지라도, 우리는 그 CNN 이 무엇을 보고 그 클라스를 그 클라스라고 판별했는지 알 수가 없었다.
이번 논문에서는 FC-Layer 의 구조를 살짝 바꾸면서 기존에 잃었던 위치 정보들을 얻어내는 'CAM' 에 대해 소개한다. 마지막 컨볼루션을 FC-layer 로 바꾸는 대신에, GAP (Global Average Pooling) 을 적용하면, 별다른 추가의 지도학습 없이 CNN 이 특정 위치들을 구별하도록 만들 수 있다는 것이다. 위 그림을 보면 CAM 을 통해 특정 클라스 이미지의 Heat Map 을 생성할 수 있다. 이 Heat Map 을 통해 CNN 이 어떻게 그 이미지를 특정 클라스로 예측했는지를 이해할 수 있다.
2. Class Activation Mapping
하나의 예시를 들자면, 우리는 CNN이 '개' 이미지를 보고 '개' 라고 예측을 할 때, 과연 그 '개' 이미지의 어떤 부분을 보고 '개' 라고 예측을 했는지에 대해 알고 싶은 것이다. Class Activation Mapping (CAM) 이란 CNN이 특정 클라스 이미지를 그 클라스라고 예측하게 한 그 이미지 내의 위치 정보를 의미한다.
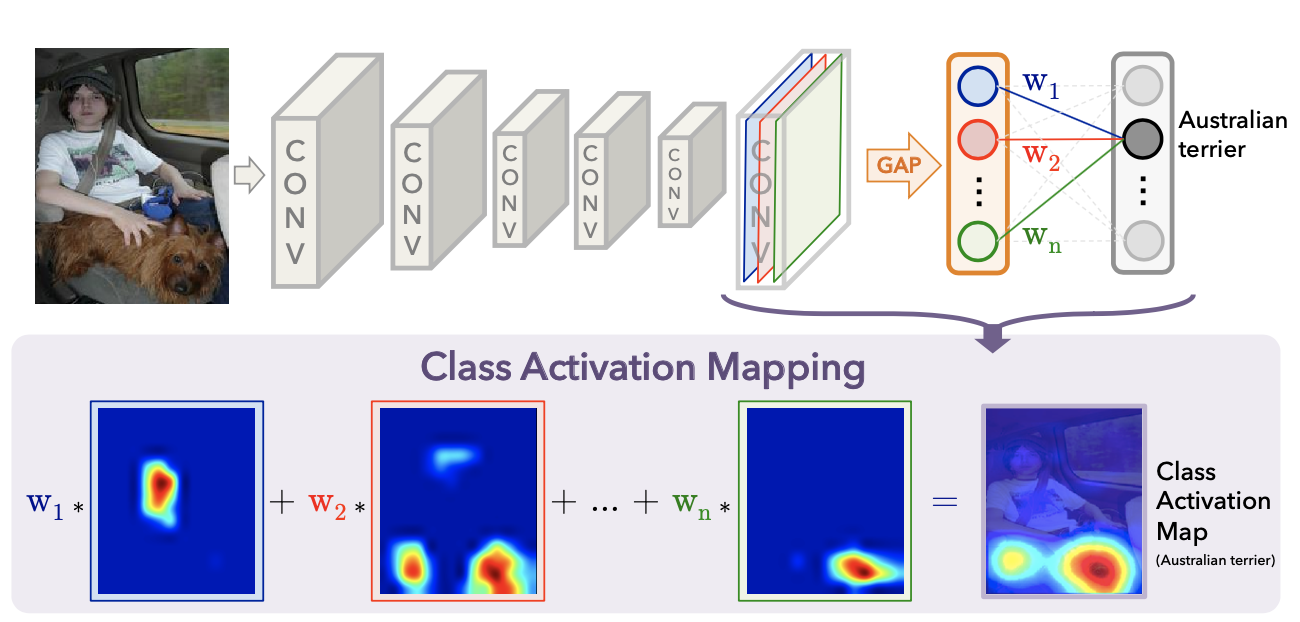
위 figure 는 CAM 과 CAM 의 네트워크 구조를 보여준다. 우선 기본적인 구조는 Network in Network 과 GoogleNet 과 흡사하다. 하지만 결정적인 차이점이 위 그림에서 볼 수 있듯이 마지막 Conv Layer 를 Fc-Layer 로 Flatten 하지 않고, GAP(Global Average Pooling) 을 통해 새로운 Weight 들을 만들어 낸다는 것이다. 마지막 Conv Layer 가 총 n 개의 channel 로 이루어져 있다면, 각각의 채널들은 GAP 를 통해 하나의 Weight 값으로 나타내고, 총 n 개의 Weight 들이 생긴다. 그리고 마지막에 Softmax 함수로 연결 돼 이 Weight 들도 백프롭을 통해 학습을 시키는 것이다.
N 개의 Weight 가 생겼다면, CAM 은 이 Weight 들을 마지막 n개의 Conv Layer 들과 Weighted Sum 을 해주면, 하나의 특정 클라스 이미지의 Heat Map 이 나오게 된다. 위 figure 의 Heat Map은 이미지 아래쪽에, 그 중에서도 오른쪽에 중요도가 표시되는 것을 볼 수 있다. 이 클라스가 'Australian terrier', 즉 개의 한 종류인데, 원래 이미지를 보면 개의 몸과 얼굴을 보고 'Austrailian terrier' 로 판단했다는 것을 확인할 수 있다.
[Global Avg. Pooling (GAP) vs Global Max Pooling(GMP)]
마지막 Conv Layer 에 GAP 혹인 GMP 를 적용함에 따라 CAM 결과에 적지 않은 영향을 끼칠 수 있다. GAP 은 네트워크가 특정 object 의 전체적인 분포를 구분할 수 있도록 도와주는 반면, GMP 은 가장 높은 특정 분포들만 구분할 수 있도록 도와준다. Classification Task 에서는 둘의 성능이 비슷하지만, Localization Task 에서는 GAP 가 더 좋은 결과를 낸다.
3. Weakly-Supervised Object Localization
우선 데이터는 ILSVRC 2014 가 사용되었다. CAM 을 활용했을 때와 원상태의 CNN 구조의 Classification 성능이 어떻게 나오는지 먼저 확인해보았다. CNN 구조는 AlexNet, VGGNet, 그리고 GoogLeNet 을 사용했다. 결과는 아래와 같다.
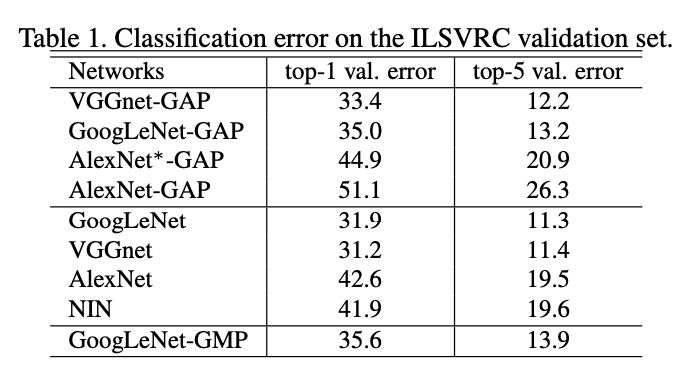
GAP 을 활용했을 때 에러가 1~2% 정도 증가하는 것을 볼 수 있다. 하지만 FC-Layer 를 전혀 사용하지 않았다는 것을 고려했을 때, 결과가 'Acceptable' 하다는 것을 볼 수 있다.

다음은 Localization 결과를 살펴보겠다. 우선 Localization 을 테스트하기 위해서 원본 이미지에서 특정 클라스의 bounding box 를 만들어야 한다. 이 bounding box 는 CAM 이 segment 된 부분 중 20% 가 넘는 부분들이 먼저 선택되었고, 이 부분들을 가장 많이 포함할 수 있는 box 가 선택되었다. 예측한 상위 5개의 클라스마다 이러한 Bounding box 를 만들었다. 위 그림을 참조하면 이해하기 쉬울 것이다.

Table 2 에서 볼 수 있듯이 CAM 을 활용한 네트워크들이 다른 네크워들보다 Localization 성능이 뛰어나다는 것을 확인할 수 있다. GoogLeNet-GAP 은 top-5 에러가 43% 밖에 되지 않았는데, bounding box 에 별다른 학습을 하지 않았다는 것을 고려할 때 매우 놀라운 결과이다.
4. Conclusion
이 논문에서 소개한 CAM(Class Activation Mapping) 은 CNN의 FC-Layer 대신 GAP 을 적용해 CNN 이 object localization 을 학습시킬 수 있도록 만들 수 있다. CAM 을 통해 우리는 특정 클라스들의 heat map 를 볼 수 있고, 이를 통해 네트워크가 이미지의 어느 부분을 보고 판단했는지 확인할 수 있다. CAM 이 놀라운 것은 별다른 지도학습 없이 heat map 를 만들어낼 수 있다는 것이다. 또한 CAM 결과를 보면 대부분 꽤나 놀라울 정도로 특정 클라스들의 feature 를 잘 추출해 낸다는 것을 확인 할 수 있다.
5. Reference
[1] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A. (2016). Learning deep features for discriminative localization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2921-2929).
'딥러닝 논문 요약' 카테고리의 다른 글
| ResNet 논문 요약/리뷰 (0) | 2020.05.11 |
|---|---|
| VGGNet 논문 요약/리뷰 (0) | 2020.05.11 |

